▲ 对 Microsoft Build 2023 上 Andrej Karpathy 演讲State of GPT的学习整理。
▲演讲 PPT 地址。
GPT Assistant 是如何训练得到的
◇ 训练过程按先后顺序分为自左至右的 4 个阶段:Pretraining、Supervised Finetuning、Reward Modeling、Reinforcement Learning。
◇ 每个阶段都涉及 3 项内容:dataset、algorithm、model,其中 model 是通过 dataset+algorithm 训练得到的。

Pretraining
◇ 预训练阶段几乎占了整个训练 99% 的运算性能与运算时间。长达数月,其他三种阶段都属于微调,训练仅消耗数天甚至数小时。
◇ 预训练得到的模型称为 base model。base model 不同于 assistant model,用于内容预测生成而不是回答问题。
◇ 预训练数据有多种来源,例如 Meta 公司的 LLaMA 模型的数据来源如下图。既有网络爬取数据,也有高质量数据集。
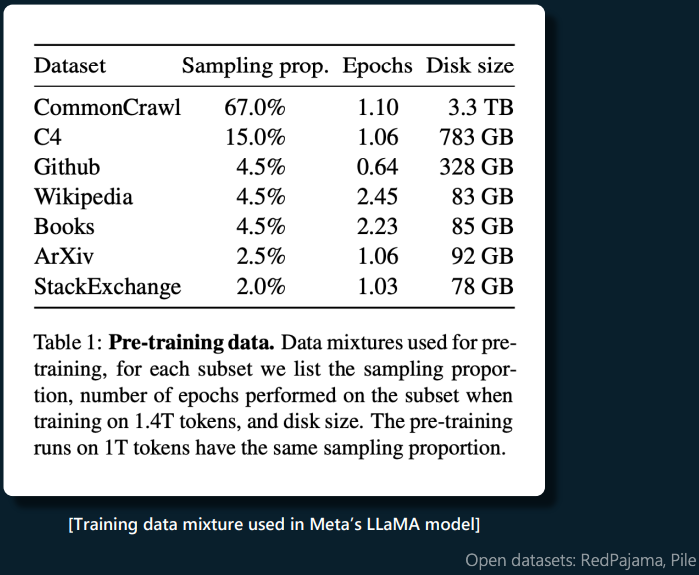
◇ 数据集内容在使用前会通过 tokenization 被转换成整数序列。

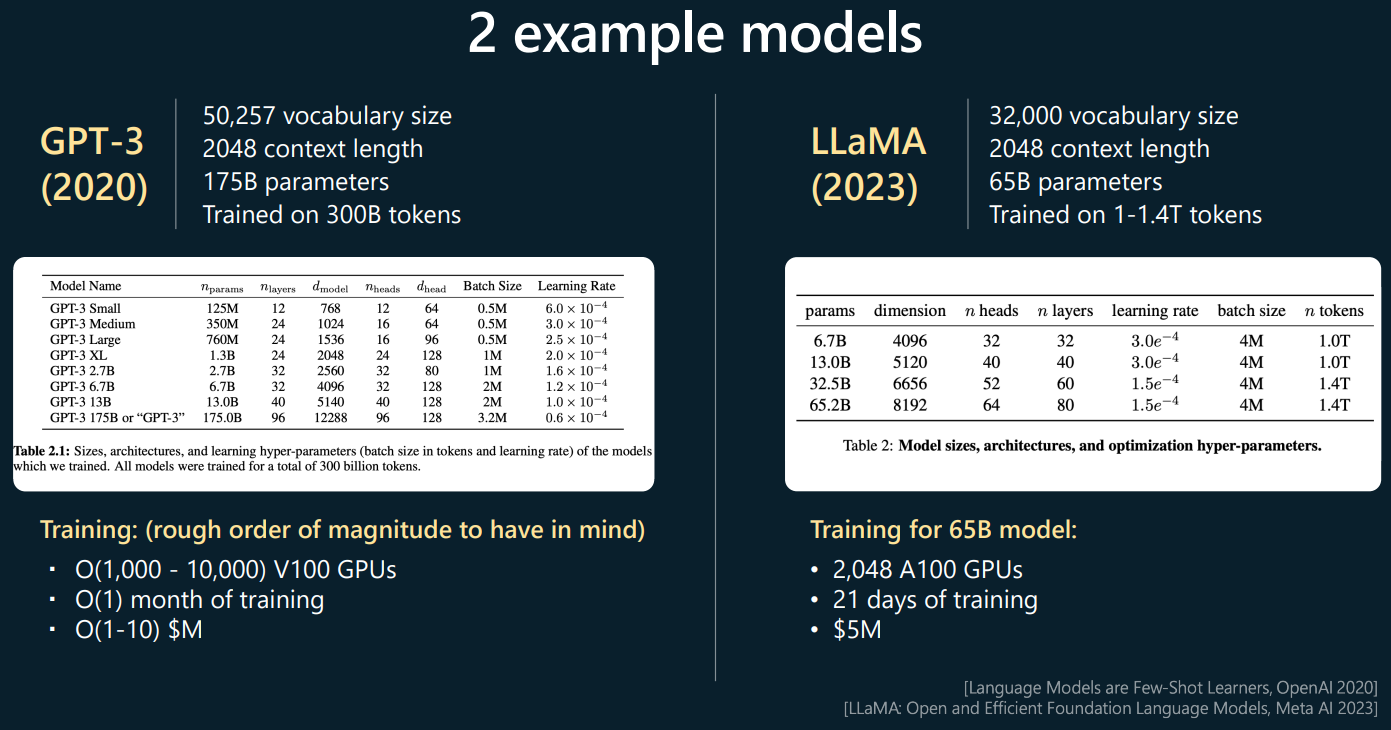
◇ LLaMA 相比 GPT-3 更擅长对大量文本数据做深入理解语义的任务(如阅读理解与问答),GPT 的优势是对写作、对话、翻译等各种通用任务都表现好。下图是 LLaMA 与 GPT-3 的训练参数的对比,其中 vocabulary size 表示训练数据包含的不重复词汇量,context length 表示训练的上下文长度,parameters 表示训练用到的参数数量,trained on tokens 表示训练数据转换成的 token 数量,可见 LLaMA 在 parameter 和 vocabulary 方面的数量更少但在 trained on tokens 方面的数量更多。模型表现受训练数据多个维度参数的影响。
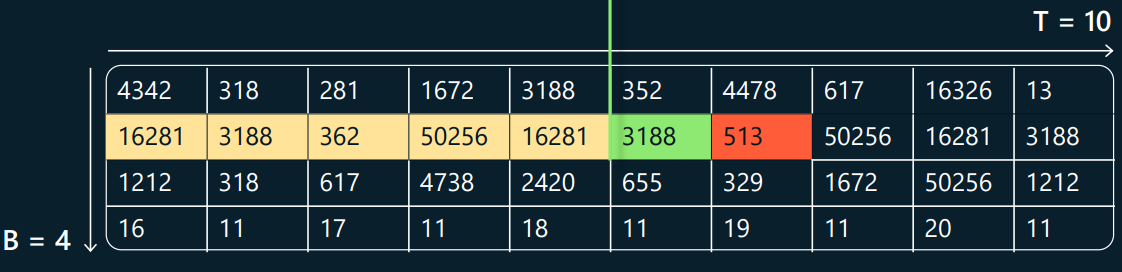
◇ 大致训练过程:训练数据被放到数组(B,T),行数 B 表示输入分为多少批,列数 T 表示最大上下文长度。数组的每一行包含多条数据序列,各条序列之间有约定好的分隔符。训练目标是让 transformer 神经网络能够在任意单元格(以图中绿格为例)根据当前及其左侧所有单元格趋于准确地推断出红色单元格的内容。
◇ 相较于传统的 NLP 模型,由于此处的 base model 在预训练过程中理解了大量文本结构与概念,针对特定任务对其进行微调时仅需较少的标注数据就能达到很好的性能。而从 GPT-2 开始,人们发现仅通过 prompt 而无需 finetuning 就能让 base model 较好完成某些特定任务,由此开启了“prompting over finetuning”的时代。
◇ GPT-2 的 base model 公布在官方 GitHub 仓库,GPT-3 的 base model 可通过官方 api 使用模型"Devanshi"调用,GPT-4 的 base model 没有发布。当前最好的 base model 是 LLaMA,但目前未支持商用。
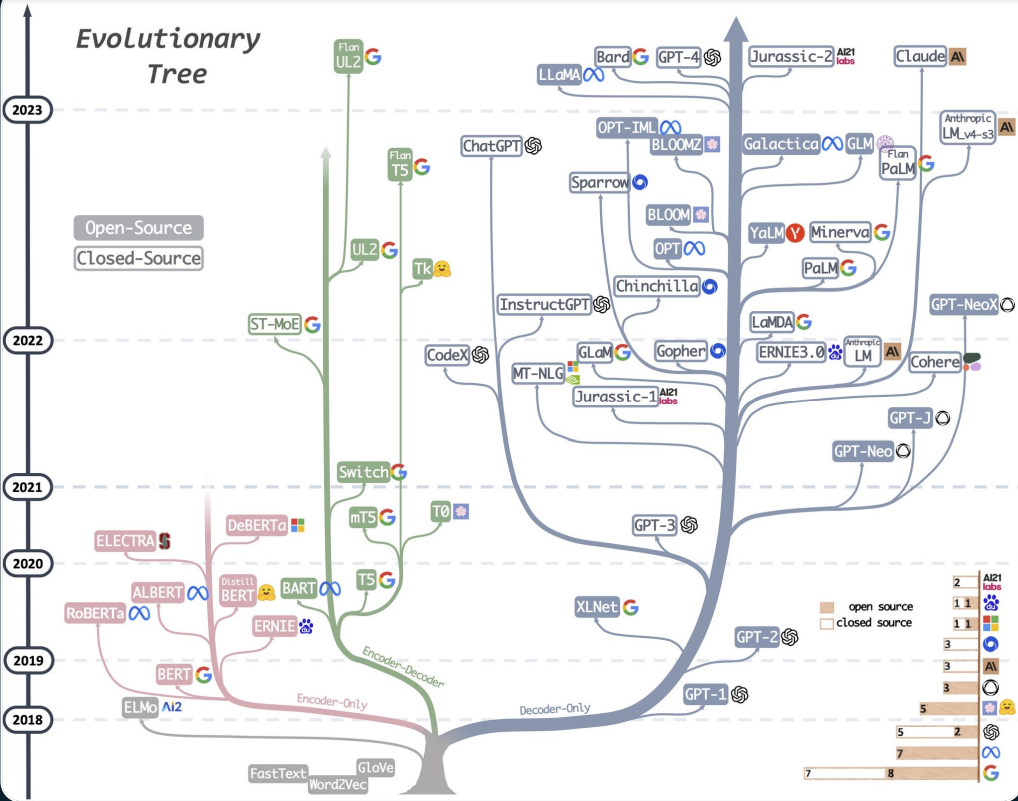
◇ 下图是当前各模型信息。
SFT(Supervised finetuning)
◆ 这一阶段的算法不变,只是数据集改成了 1-10 万数量的高质量"prompt+response"的问答示例,以向 assistant model 的方向训练。
◆ 训练结果模型称为 SFT model。
RLHF(reinforcement learning from human feedback )
□ RLHF 由 Reward modeling 和 Reinforcement learning 两个阶段组成。
□ Reward modeling 阶段的数据集量级在 10-100 万,内容是:上阶段 SFT model 对同一个 prompt 回答的多次 response+人为指定的效果分数排序。以此指导模型能针对一个 prompt 给相应的 response 打分。此阶段得到的模型称为 RM model。
□ Reinforcement learning 阶段的数据集量级在 1-10 万,内容是:prompt+SFT model 的多次回答+RM model 对相应回答的打分。以此强化模型针对 prompt 给出分数更高的 response。
□ 经过 RLHF 得到的模型称为 RLHF model。ChatGPT 就属于 RLHF model。
□ RLHF 提高了模型的结果分数但也使其丧失了部分多样性(variation),于是在已知 N 个目标输出样例并期望得到具有更多多样性输出的场景,可以考虑使用 base model。
□ https://lmsys.org 网站提供了大语言模型(LLM)的竞技场(https://chat.lmsys.org/),并会定期发布排名结果到blog(如:https://lmsys.org/blog/2023-12-07-leaderboard/),目前排名靠前的模型都是RLHF model。
实践中如何有效使用 GPT assistant
■ 不同于人类从问题到答案的思维过程,transformer 的"think"是 tokens 维度的,它得出答案的过程是不断得基于现有 token(s) 预测下个 token。因此,当问题的回答需要推理时,通过将问题拆分步骤(Chain-of-Thought)的方式减少问题中每个 token 需要推理的数量,能得到更好的答案。拆分方式有两种:
(1)prompt 中按照拆分步骤的方式提供一组问答样例
(2)prompt 中说明"分步骤思考"(“think step by step”)

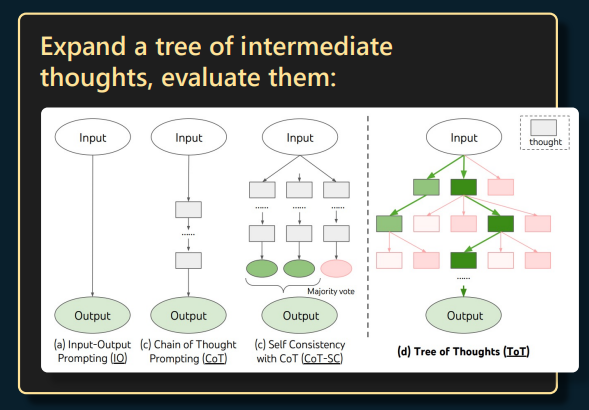
■ 当生成答案期间如果有一个 token 偏离了问题,transformer 不会返回检查纠正而是继续基于已生成 token 继续生成后续内容。但可以通过带上历史问答内容重新提问上次回答是否满足提问需求使它对上次回答检查并返回纠正后的回答。目前有称为"Tree of Thoughts"方向的研究,目的是将许多 prompts 与树检索算法结合以动态得到最优的生成答案从而避免出现需要纠正的情况。
■ LLM 的"心理癖好":LLM 仅倾向于模仿所有相关训练数据生成完整答案而不会对训练数据中不同级别的答案做区分,比如对于一个物理问题,训练数据中通常既有专家级别的答案也有学生级别的答案甚至还有开玩笑的答案,LLM 默认会同时模仿所有级别的答案,这时可通过设置“Let's work this out in a step by step way to be sure we have the right answer.”、“You're a leading expert on this topic.”、“Pretend you have IQ 120.”这样的 prompt 来排除对低质量答案的模仿。
■ 为 LLM 指定可以使用的 tools(or plugin) 的场景中,在 prompt 中告诉 LLM 不擅长对应 tool 的能力可以让 tool 的调用更准确,因为 LLM 并不知道它自己不擅长的方面。
■ 检索增强(retrieval-augmented)的 LLM,LLM 只有从训练数据得来的知识记忆(memory),如果将检索得到的提问相关信息放入 LLM 的上下文窗口(可称为 working memory)就可以同时发挥两者优势得到更好的答案。当前出现的方案是将信息分块后存入向量存储(如 LlamaIndex),针对提问先检索得到相关信息再将其组织成 prompt。
■ 在希望限制 LLM 按照固定模板格式输出结果的场景,可以使用guidance。
■ finetuning 的本质是更新模型的参数权重,涉及更多专业技术,已知优化策略与相关工具:
(1)Parameter Efficient Finetuning(PEFT)。PEFT 是深度学习领域的一种优化策略,目标是在微调过程中尽可能减少需要更新的参数数量,而让模型的大部分参数权重固定,从而大幅降低 finetuning 成本。工具如:LoRA。
(2)Low-precision inference(低精度推理)。低精度推理是深度学习领域的一种优化策略,通过降低模型权重和激活的精度,减少模型的内存占用和计算需求而提高运行速度,在模型训练/微调完成后使用。结合前面 PEFT 只针对微调部分做低精度推理也可降低计算成本。工具如:bitsandbytes。
■ 目前的 LLM 适合应用在与人为监督相结合的低风险领域,如灵感、建议、copilot。
来自 GPT-4 的激励
